深度剖析:聊聊英特尔与AMD各自不同的CPU整合思路,谁更胜一筹?
遗憾的是,如今这只回放镖又狠狠砸在了英特尔自己的脸上。因为短短几年之后,这家x86就开始寻求自己的一套芯片整合方案。
从今年开始,英特尔的至强6处理器开始分阶段推出,这意味着英特尔第三代多芯片至强和首款采用与AMD独特异构芯片架构的数据中心处理器也走上了自己当初曾经嘲笑过的技术路线。
虽然英特尔最终也不得不在AMD的芯片战略前低下高傲的头,但采取的方法却与这位老对手截然不同。
克服掩模版极限
在深入讨论这个话题之前,我们先来聊聊为什么新一代CPU设计纷纷放弃传统单片架构。这主要归结于两大因素:掩模版极限与产能容量。
总的来讲,在制程工艺技术缺乏重大改进的情况下,更多核心必须对应着更多芯片。然而,芯片的物理尺寸面对客观极限——我们将其称为掩模版极限,大致为800平方毫米。一旦达到这一极限,那么继续扩展计算能力的唯一方法就是引入更多芯片。
我们现在已经看到大量产品(不仅仅是CPU)在采用这种方法,它们将两块大型芯片塞进同一封装之内。Gaudi 3、英伟达的Blackwell乃至英特尔的Emerald Rapids至强都是这种技术路线的典型代表。
多芯片设计的问题在于,各芯片之间的桥接机制往往会造成传输带宽瓶颈,并很可能引入额外的延迟。虽然情况还不至于像把工作负载分散到多个插槽那么严重,但实际影响也已相当显著,因此一部分芯片设计师更倾向于使用较少数量的大型芯片来实现计算能力扩展。
然而,这种较大芯片的制造同样非常昂贵,这是因为芯片尺寸越大、其缺陷率就越高。于是乎,使用数量更多但尺寸较小的芯片也成了有吸引力的方向,这也解释了AMD为什么会在设计当中使用这么多的芯粒——在最新的Epyc型号中,芯片数量已经高达17个。
聊完了以上背景知识,接下来我们就将深入探讨英特尔和AMD分别在其最新至强和Epyc处理器中采取的不同设计理念。
AMD的老套路
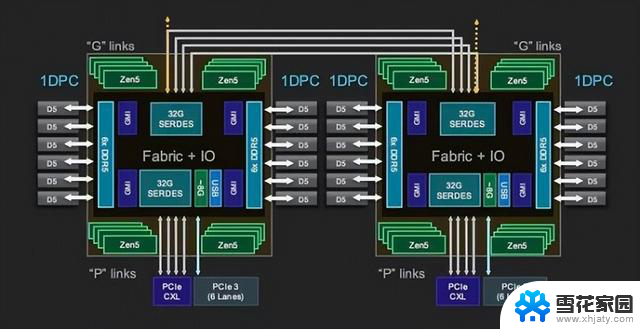
我们先从AMD的第五代Epyc Turin处理器说起。具体来看,我们关注的是该芯片的128核Zen 5版本,其拥有16个4纳米核心复合芯片(CCD),同时辅以基于台积电6纳米制程工艺制造的单块I/O芯片(IOD)。

AMD最新一代Epyc配备多达16个计算芯片
可能很多朋友觉得这个数字听起来耳熟,这是因为AMD在其第二代Epyc处理器上使用了基本相同的设计方案。作为比照,第一代Epyc就没有单独的I/O芯片。
正如前文已经提到,使用大量较小的计算芯片,意味着AMD能够获得更高的产量,同时也能保证在Ryzen和Epyc处理器之间实现芯片共享。

这些芯粒看着是不是似曾相识,
那是因为AMD的Epyc和Ryzen处理器实际上使用着相同的计算芯片。
此外,在采用8核或16核CCD且各自对应32 MB L3缓存的情况下,AMD还能够以更大的灵活性按缓存及内存等比例扩展核心数量。
举例来说,如果我们需要一块拥有16个核心的Epyc(受到软件许可条款的限制。这也是高性能计算工作负载领域最常见的SKU配置),那么达成目标的最佳方式自然就是使用两个八核心CCD,且二者共享64 MB的L3缓存。当然,我们也可以使用16个CCD,每CCD对应一个活动核心,同时内置512 MB缓存。虽然听起来很疯狂,但这两种设计方案其实都存在。
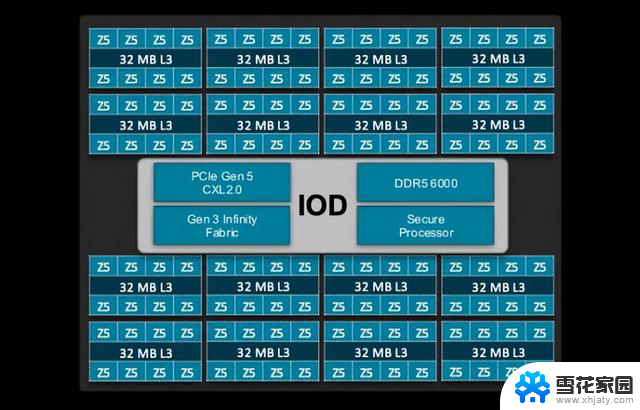
AMD的第五代Epyc处理器遵循传统模式,将16个计算核心围绕单一中央I/O芯片布置而成。
另一方面,I/O芯片则负责除计算之外的几乎所有管理任务,包括内存、安全性、PCIe、CXL以及其他I/O(例如SATA),同时承载芯片CCD与其他插槽之间的骨干通信。
AMD Epyc Turin I/O芯片细节示意图。
将内存控制器放置在I/O芯片之上既有优点、也有短板。从好的方面来看,这意味着内存带宽大大多数情况下能够独立于核心数量进行扩展。但缺点是某些工作负载的内存和缓存访问延迟可能会更高。这里之所以强调“可能更高”,是因为具体情况往往要视具体工作负载而定。
至强的芯粒探索之旅
话题来到英特尔这边,这家芯片制造商对于多芯片处理器的设计处理跟AMD有着很大不同。虽然现代至强处理器也采用计算与I/O芯片彼此独立的异构架构,但只在特定型号上才会出现。
英特尔的第一款多芯片至强处理器代号为Sapphire Rapids,采用一块单体中等核心数量的芯片或者四块极端追求高核心数量的芯片,每块芯片都拥有自己的内存控制器与内置I/O功能。Emerald Rapids虽然也采用了类似的设计模式,但在核心数量更高的SKU上使用了两块尺寸更大的芯片。

如图所示,在Sapphire和Emerald Rapids之间,英特尔将四块中等尺寸的芯片换成了两对几乎以网状排布的更大芯片。
而所有这一切都随着至强6的变相而有所转变,这一次英特尔将I/O、UPI链接乃至加速器转移到了两块基于Intel 7制程工艺制造的芯片之上,而中央位置部署的则是采用Intel 3制程工艺的一到三块计算芯片。
出于我们稍后会具体讨论的原因,这里先关注被英特尔寄予厚望的Granite Rapids至强6处理器,姑且将多核心Sierra Forest放到一边。
观察英特尔的计算芯片,我们就会发现它与AMD的一大主要区别,就在于每个计算模块至少有43个内置核心,且可以根据SKU进行开启和关闭。也就是说在同样实现128个核心的情况下,英特尔需要的芯片数量要比AMD少得多;但由于前者单块芯片的尺寸更大,因此制造良品率肯定也会相应降低。

根据不同SKU配置,Granite Rapids会在两块I/O芯片之间放置一到三块计算芯片。
除了更多的核心之外,英特尔还选择将这些芯片的内存控制器放置在计算芯片本体之上,每芯片支持四条通道。这种设计理论上应该能够降低访问延迟,但同时也意味着如果希望获得全部12条内存通道,则必须选择拥有三块计算芯片的版本。
至于之前报道过的6900P系列系统,大家倒不用担心这个问题,因为其所有SKU都配置三块板载计算芯片。但由此也可以看出,其72核版本只使用到了封装中的一小部分芯片。同样的,我们之前讨论过的面向高性能计算中心的16核Epyc也是如此。
另一方面,英特尔的6700P系列系统将于明年年初推出,计划配备一到两块计算芯片,具体取决于客户需要的内存带宽和核心数量。也就是说内存将被限制为最高8条通道,而配备单块板载计算芯片时只能只有4条通道。我们目前还不太清楚HCC和LCC芯片上的内存配置,不排除英特尔可能增强了这些部件之上的内存控制器。
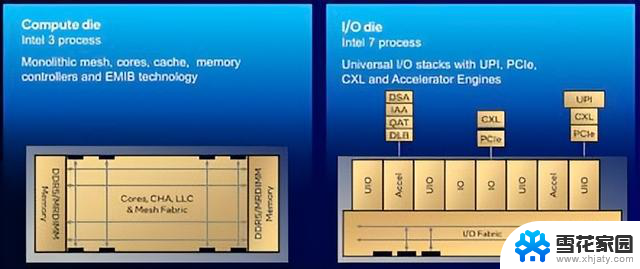
与AMD的Epyc一样,英特尔的至强处理器现在采用同时带有计算和I/O芯片的异构设计架构
英特尔的I/O芯片设计则相当轻薄,主要承载PCIe、CXL和UPI链路组合,用于同存储、外设及其他插槽进行通信。除此之外,我们还发现了大量用于直接流(DSA)、内存分析(IAA)、加密/解密(QAT)以及负载均衡的加速器。
据了解,英特尔之所以选择在I/O芯片之上放置加速器,部分原因是想将其放置在更靠近数据的位置,保证数据能够高效流入/流出芯片。
接下来的发展将向何处去?
从表面上看,英特尔的下一代多核处理器代号为Clearwater Forest,将于明年上半年推出。其外形与Granite Rapids类似,拥有两块I/O芯片和三个计算模块。

整款产品看起来就如同缩小版的Granite Rapids,但这反映的显然只是芯片结构,底层还隐藏着更多芯粒。
然而,眼见有时也未必为实。据我们了解,这三块计算芯片实际上只是芯片结构,其下还隐藏着更多较小的计算芯片,这些芯粒被布置在有源芯片中介层之上。
从英特尔今年早些时候放出的展示效果图来看,Clearwater Forest的每封装最多可以容纳12个计算芯片。使用芯片中介层也已经不新鲜,这能带来诸多好处,包括相较常规基板提供更高的芯片间带宽和更低延迟等。有些朋友可能已经看出,这种设计与英特尔此前核心数量最高的Sierra Forest 144核计算芯片可谓是大相径庭。

从英特尔今年晚些时候发布的渲染图来看,Clearwater Forest中的隐藏芯粒可能要比Granite Rapids多得多。
当然,我们从渲染图中只能看到Clearwater Forest相关技术的一丝端倪,并不代表其明年真的就会与广大用户见面。
而且更大的问题可能在于,AMD下一步究竟会把其芯粒架构带向何方。观察AMD的128核Turin处理器,就会发现封装之内已经没有太多空间可以容纳更多芯片;只有Zen处理器家族还有一定腾挪的余地。
首先,AMD可以选择更大的封装,为额外的芯粒腾出空间。或者,这家芯片制造商也可以将更多核心封装进大量芯粒之内。然而,我们猜测AMD的第六代Epyc,最终看起来可能会更类似于其Insinct MI300系列加速器。

MI300A将24个Zen 4核心、6个CDNA 3 GPU芯片以及128 GB HBM3内存集成到了同一面向高性能计算工作负载的封装之内。
大家可能还记得,当初与MI300 X GPU一同推出的还有一款APU,它将芯片中的两个CDNA3模块换成了三个CCD,对应24个Zen 4计算核心。其这些计算模块堆叠在四个I/O芯片之上,再连接到八个HBM3模块组当中。
虽然目前还只是猜测,但AMD后续采用类似的设计也完全在情理之中,例如用额外的CCD替换掉全部内存和GPU芯片。这样的设计肯定能够带来更高的传输带宽和更低的芯片间通信延迟。
实际答案是否正确,只有留给时间去慢慢证明。我们预计AMD的第六代Epyc处理器将于2026年底正式投放市场。
深度剖析:聊聊英特尔与AMD各自不同的CPU整合思路,谁更胜一筹?相关教程
-
 AMD锐龙7 8700F与锐龙5 8400F:性能背后的AI革新之路,谁更胜一筹?
AMD锐龙7 8700F与锐龙5 8400F:性能背后的AI革新之路,谁更胜一筹?2024-04-17
-
 美国欲推动Intel与AMD合并,英特尔巨额亏损引发关注
美国欲推动Intel与AMD合并,英特尔巨额亏损引发关注2024-11-05
-
 英伟达/AMD/英特尔的哪些芯片将受限?- 热门芯片限制分析
英伟达/AMD/英特尔的哪些芯片将受限?- 热门芯片限制分析2023-10-19
-
 AMD与英伟达计划于2025年发布消费级Arm架构CPU,英特尔面临巨大挑战
AMD与英伟达计划于2025年发布消费级Arm架构CPU,英特尔面临巨大挑战2023-10-24
- 英特尔CEO强调“我们还活着,X86没过时”,首次与AMD合作,高通收购疑云笼罩
- 一年发两代至强服务器CPU,英特尔在卷什么?解析最新收益及市场份额
- CPU为何被称为人造物的巅峰?网友深度解析,令人大开眼界!
- 英特尔Battlemage GPU消息汇总 能打AMD英伟达吗?细节曝光
- NVIDIA NeMo和triton区别:一文解析NeMo和triton的不同特点
- AMD与英伟达AI芯片市场巅峰对决,谁将称王?
- 每小时用8度电,NVIDIA Blackwell B200又一参数细节曝光!- 最新消息
- 2024年手机CPU性能排名:骁龙8至尊版称霸,A18Pro仅列第三
- 消息称FTC准备对微软云计算业务展开反竞争行为调查,微软云计算业务或将面临反竞争调查
- 英特尔至强6性能核处理器:重返数据中心CPU王座!
- 微软总裁史密斯:中国在技术发展领域正赶超西方,技术实力逐渐崛起
- 手机处理器分段?网友:从低到高,CPU段位大揭秘!手机处理器排名一览
系统资讯推荐
- 1 每小时用8度电,NVIDIA Blackwell B200又一参数细节曝光!- 最新消息
- 2 消息称FTC准备对微软云计算业务展开反竞争行为调查,微软云计算业务或将面临反竞争调查
- 3 NVIDIA App整合GeForce Experience和控制面板,Beta测试结束
- 4 详细步骤教你如何安装Win10系统,轻松搞定安装Win10系统的方法
- 5 详细步骤教你如何安全更换电脑CPU,实用指南
- 6 如何有效升级显卡以提升游戏性能和视觉体验,游戏显卡升级攻略
- 7 详细步骤教你如何安装Windows系统并解决常见问题,轻松搞定电脑重装
- 8 英特尔Battlemage GPU消息汇总 能打AMD英伟达吗?细节曝光
- 9 英伟达超越苹果,成为市值3.6万亿美元的首家上市公司历史性时刻
- 10 现役旗舰顶级CPU风冷!吊不吊,你说了算!最全面评测
win10系统推荐
系统教程推荐
- 1 win7如何进pe系统 win7怎么制作pe系统
- 2 xp系统改win7系统步骤 XP系统换成win7系统方法
- 3 win11edge消息推送电脑怎么打开 弘电脑如何设置动态提醒和回复通知
- 4 win11锁屏后如何让屏幕一直亮着 Win11怎么设置屏幕常亮时间
- 5 win10系统能用f12一键还原吗 戴尔按f12恢复系统操作步骤
- 6 增值税开票软件怎么改开票人 增值税开票系统开票人修改方法
- 7 网格对齐选项怎么取消 网格对齐选项在哪里取消
- 8 电脑桌面声音的图标没了 怎么办 电脑音量调节器不见了怎么办
- 9 键盘中win是那个键 电脑键盘win键在哪个位置
- 10 电脑如何连接隐藏的wifi网络 电脑如何连接隐藏的无线WiFi信号