英伟达显卡性能对比:H100、A100和4090性能分析及应用场景详解
 二、技术解析与应用场景1. H100:卓越的高性能计算与深度学习显卡
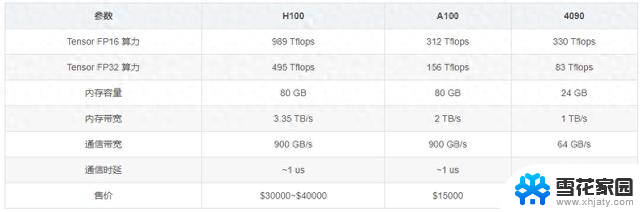
二、技术解析与应用场景1. H100:卓越的高性能计算与深度学习显卡H100作为NVIDIA最新一代的旗舰级显卡,拥有惊人的1979 Tflops Tensor FP16算力和989 Tflops Tensor FP32算力。这使得它在处理复杂的深度学习任务时表现尤为出色。其80 GB的大容量显存和3.35 TB/s的内存带宽能够快速处理海量数据,而900 GB/s的通信带宽和~1 us的低通信时延确保了高效的数据传输。
应用场景:
深度学习模型训练:H100的高算力和大带宽非常适合用于训练大型深度学习模型,特别是在自然语言处理(NLP)和计算机视觉(CV)领域。
科学计算与仿真:高性能计算(HPC)领域的科学研究和工程仿真,如气候建模、药物研发等,都能受益于H100的强大性能。
大规模数据分析:对于需要处理和分析大规模数据集的任务,如金融分析、基因组学等,H100提供了充足的算力和存储带宽。
2. A100:平衡性能与成本的高效解决方案A100是H100的前代产品,尽管其性能稍逊一筹。但其312 Tflops的Tensor FP16算力和156 Tflops的Tensor FP32算力仍然十分强劲。与H100相同的80 GB显存和900 GB/s通信带宽使得它在很多应用场景中依旧具有很高的性价比。
应用场景:
深度学习推理:对于已训练好的深度学习模型,A100在推理阶段表现出色,能够快速响应和处理大量推理请求。
数据中心工作负载:A100在数据中心中可以支持多种工作负载,包括AI、数据分析和传统的HPC任务。
云计算平台:由于其相对较低的成本,A100成为许多云服务提供商的首选显卡,用于构建高效的云计算平台。
3. 4090:游戏与轻量级计算的性价比之选4090是NVIDIA面向游戏和消费市场的高端显卡,拥有330 Tflops的Tensor FP16算力和83 Tflops的Tensor FP32算力。尽管性能不如H100和A100,但其24 GB显存和1 TB/s的内存带宽在许多应用中已经足够。64 GB/s的通信带宽和~10 us的通信时延也满足了多数非高性能计算任务的需求。
应用场景:
高端游戏:4090专为高端游戏设计,能够在4K分辨率下提供流畅的游戏体验。
视频编辑与渲染:视频编辑和3D渲染等任务需要较高的图形处理能力,4090可以高效完成这些工作。
轻量级AI任务:对于一些不需要超高算力的AI任务,如图像分类、物体检测等,4090也是一个不错的选择。
三、性能与应用的综合分析从上述对比和应用场景可以看出,H100、A100和4090各有其独特的优势和适用场景。H100作为顶级显卡,适用于要求最高性能的任务,而A100则在性能和成本之间找到了平衡,适合广泛的应用场景。4090尽管主要面向游戏市场,但其强劲的性能也能胜任许多专业任务。
1. 性能优势H100:极高的Tensor算力和内存带宽,使其在深度学习和科学计算领域无可匹敌。
A100:具备足够的性能处理大多数AI和HPC任务,同时成本相对可控。
4090:适合游戏和多媒体处理,也能应对轻量级的AI和计算任务。
2. 价格考虑H100的价格在$30000到$40000之间,适合预算充足且对性能要求极高的用户。
A100的价格约为$15000,是高性能和成本的良好平衡点。
4090仅需$1600,对于一般用户和中小型企业而言,性价比极高。
四、总结与未来展望通过对H100、A100和4090三款显卡的详细对比和应用分析,我们可以看出,不同显卡在性能、带宽、时延和价格上的差异决定了其在不同应用场景中的适用性。未来,随着技术的不断进步,我们可以期待更高性能、更低功耗的显卡问世,从而进一步推动AI、HPC和各类计算任务的发展。
对于开发者和研究人员而言,选择合适的显卡将直接影响到项目的效率和成果。在考虑预算的前提下,根据具体需求选择最适合的显卡,是实现项目成功的关键一步。
英伟达显卡性能对比:H100、A100和4090性能分析及应用场景详解相关教程
-
 英伟达显卡(NVIDIA)和AMD显卡的性能对比及选购指南
英伟达显卡(NVIDIA)和AMD显卡的性能对比及选购指南2024-06-04
-
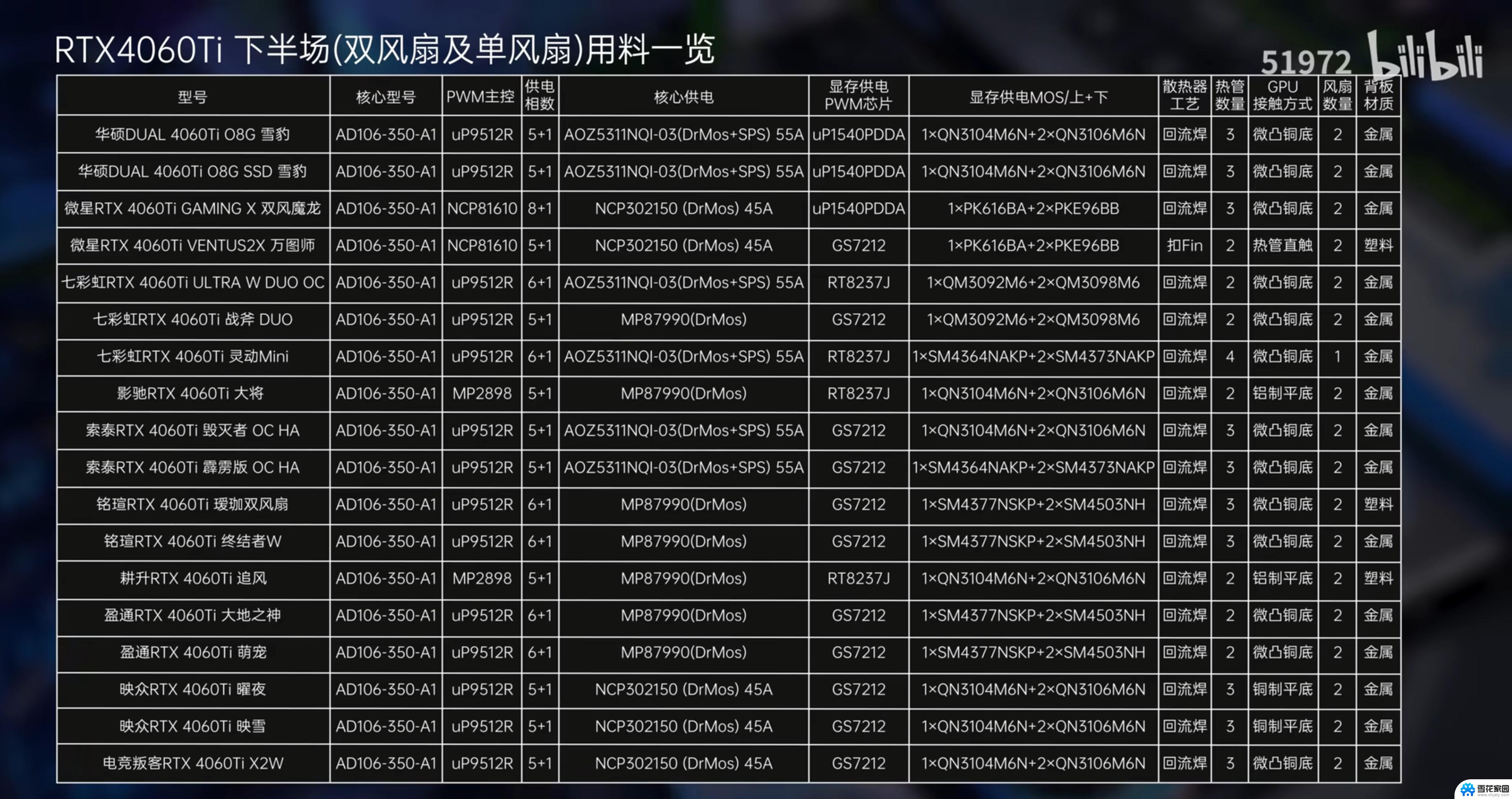 G显卡性能评测与用户体验分析:值得购买吗?-详细分析G显卡性能表现及用户反馈,购买前必读
G显卡性能评测与用户体验分析:值得购买吗?-详细分析G显卡性能表现及用户反馈,购买前必读2024-10-28
-
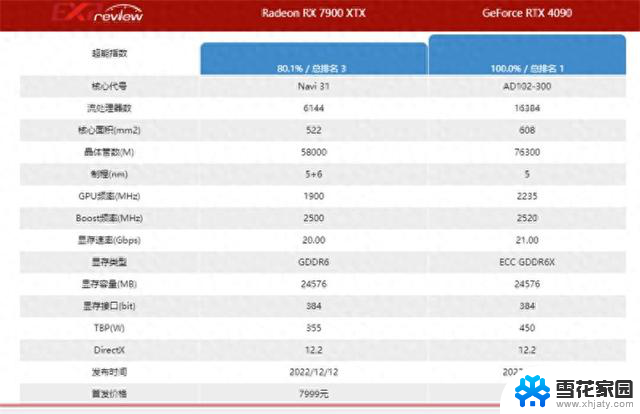 技嘉RX7900XTX显卡性能解析:相当于英伟达多少?
技嘉RX7900XTX显卡性能解析:相当于英伟达多少?2024-06-12
-
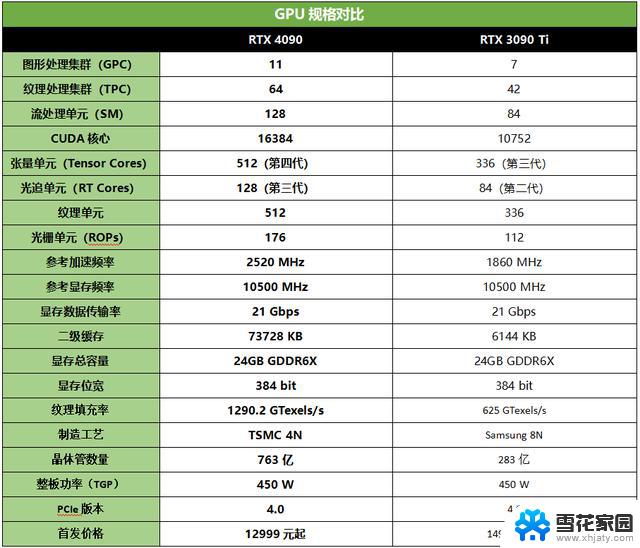
- CS240款显卡性能测试:4060Ti竟不敌3060Ti,性能对比一览
- AI插帧技术助力英伟达游戏表现,高性能显卡仍然必不可少
- 2023年12月最新电脑CPU性价比天梯图及单核、多核性能对比
- 1050显卡性能评测:游戏体验与性价比分析,看看这款显卡在游戏中的表现如何
- 英伟达官网移除RTX 4090显卡信息,中国市场或将停售
- 预算比较充足上哪块CPU好?INTEL 13600KF实测性能评测及价格分析
- 每小时用8度电,NVIDIA Blackwell B200又一参数细节曝光!- 最新消息
- 2024年手机CPU性能排名:骁龙8至尊版称霸,A18Pro仅列第三
- 消息称FTC准备对微软云计算业务展开反竞争行为调查,微软云计算业务或将面临反竞争调查
- 英特尔至强6性能核处理器:重返数据中心CPU王座!
- 微软总裁史密斯:中国在技术发展领域正赶超西方,技术实力逐渐崛起
- 手机处理器分段?网友:从低到高,CPU段位大揭秘!手机处理器排名一览
系统资讯推荐
- 1 每小时用8度电,NVIDIA Blackwell B200又一参数细节曝光!- 最新消息
- 2 消息称FTC准备对微软云计算业务展开反竞争行为调查,微软云计算业务或将面临反竞争调查
- 3 NVIDIA App整合GeForce Experience和控制面板,Beta测试结束
- 4 详细步骤教你如何安装Win10系统,轻松搞定安装Win10系统的方法
- 5 详细步骤教你如何安全更换电脑CPU,实用指南
- 6 如何有效升级显卡以提升游戏性能和视觉体验,游戏显卡升级攻略
- 7 详细步骤教你如何安装Windows系统并解决常见问题,轻松搞定电脑重装
- 8 英特尔Battlemage GPU消息汇总 能打AMD英伟达吗?细节曝光
- 9 英伟达超越苹果,成为市值3.6万亿美元的首家上市公司历史性时刻
- 10 现役旗舰顶级CPU风冷!吊不吊,你说了算!最全面评测
win10系统推荐