微软计划使用SignalR和其他开源工具构建AI驱动的Microsoft Copilot
Microsoft Copilot 由多个开源工具提供支持,例如:SignalR、自适应卡片、Markdown 和对象盆地,以解决大规模构建支持 AI 的应用程序的独特挑战。在本文中,我们将分享设计注意事项以及如何集成各种工具。更具体地说,本文重点介绍我们如何将消息和响应流式传输到前端 UI 的各个方面,同时概述服务器端发生的情况。随着越来越多的团队和企业考虑利用大型语言模型 (LLMs),我们希望本文有助于扩展 AI 生态系统。
概述Microsoft Copilot 可在移动应用程序、必应等许多表面上使用,并且它内置于 Microsoft Edge 侧边栏中,为 Edge 用户提供轻松访问。它提供了流畅的对话体验,增强了传统的网络搜索和浏览体验。由于 Microsoft Copilot 由 AI 提供支持并驻留在 Edge 浏览器中,因此用户可以提出以自然人类语言形成的复杂问题,甚至可以在浏览 Web 时需要获得创意源泉时获得帮助。在幕后,最先进的 AI 模型通过考虑用户当前的浏览上下文并合成 Web 来生成响应。除了文本输入和输出之外,用户还可以使用语音和图像与 Microsoft Copilot 进行通信,以实现更丰富的交互。
大纲使用 SignalR 建立低延迟通信通道
使用自适应卡片 + Markdown 描述和呈现 UI
申请流程
深入探讨:我们如何使用 SignalR?
下一步是什么?
使用 SignalR 建立低延迟通信通道等待 AI 模型生成完整响应后再将其发送回客户端是不切实际的。我们需要的是一种让服务器以块形式流式传输响应的方法,以便用户可以尽快看到部分结果。虽然我们无法更改生成完整响应所需的时间,但我们希望提供近乎实时的感知响应时间。我们首先研究了服务器发送事件,因为它是 OpenAI 选择的协议,我们的一些团队成员在 Python 中也有使用它的经验。但是,我们最终决定不这样做,原因有两个:
我们从从事 Azure 服务的同事那里了解到,他们已经看到有关 SSE 被代理阻止的报告。
我们想添加一项功能,允许用户打断 AI 模型的进一步响应。当从 AI 模型生成极长的响应时,这会派上用场。SSE 是一种单向协议,在这里帮不上什么忙。
初步调查使我们对需要实现的目标有了更深入的了解 - 客户端和服务器之间的通信通道具有四个关键特征:
低延迟
网络容错
易于扩展
双向(服务器和客户端都可以在需要时来回发送消息)
SignalR 似乎几乎完全符合描述。它会自动检测并在各种 Web 标准协议和技术中选择最佳传输方法。默认情况下,WebSocket 用作传输方法,它优雅地回退到服务器发送的事件和长轮询技术,以满足客户端的能力。
使用 SignalR 库,我们无需担心使用哪种传输协议,我们可以超越网络级别的问题,专注于实现核心业务逻辑,该逻辑以各种数据格式生成有用的响应。我们的团队可以在安全的假设下运作,即实时通信渠道已经建立并得到照顾。对我们来说,另一个方便的好处是 SignalR 是 ASP.NET Core 的一部分,我们不需要新的后端依赖项。
使用自适应卡片 + Markdown 描述和呈现 UI大多数消息都使用自适应卡片,因为可以有 Markdown。这有助于我们支持和控制如何以标准方式显示许多内容,例如代码块、链接、图像和样式文本。“自适应卡片是与平台无关的 UI 片段,以 JSON 编写,应用和服务可以公开交换。当交付到特定应用时,JSON 将转换为自动适应其周围环境的本机 UI。它有助于为所有主要平台和框架设计和集成轻量级 UI。(摘自 https://adaptivecards.io)。
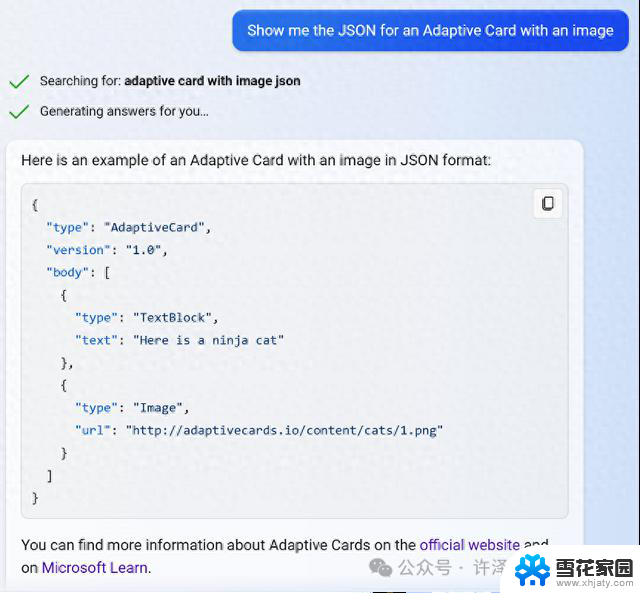
使用自适应卡片的响应示例,其中包含显示自适应卡片的 JSON 的代码块。
我们在后端使用标准的自适应卡片架构对象,以便各种组件可以控制与前端共享的内容。例如,在模型生成响应后,我们后端的组件可以轻松地在生成的文本上方添加图像。
申请流程文本输入 -> 文本输出用户可以使用关键字键入其输入消息。该页面使用 SignalR 通过 WebSocket 与名为 /ChatHub 的终结点进行通信。 /ChatHub 终结点接受一个请求,其中包含有关用户及其消息的元数据。 /ChatHub 发回带有响应的事件,供客户端处理或显示。
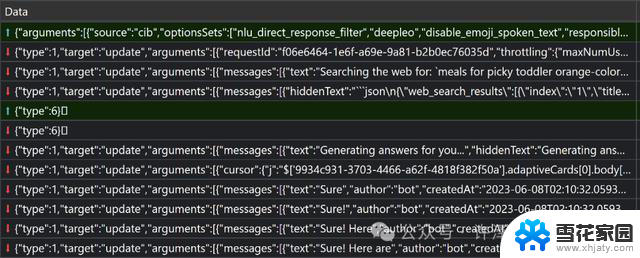
当您说“我可以为只吃橙色食物的挑剔的幼儿做些什么饭菜”时,事件通过 WebSocket 连接流式传输。第一行是来自客户端(前端)的请求。以下内容是来自服务的响应。它们包括要在聊天窗口中显示的每个项目的消息对象。我们将在本文后面详细介绍它们。
该页面使用 FAST 在生成和接收消息时有效地更新页面 /ChatHub 。
语音输入 - >语音输出用户还可以使用语音提供输入,Microsoft Copilot 将读出响应。
为了处理语音输入,我们使用与必应相同的语音识别服务,并且多年来一直在改进。一开始,在客户端和我们的后端之间,我们只是放置了语音识别服务,它充当反向代理。该服务将语音转换为文本,并将其作为提示发送到我们的后端。从后端返回响应后,语音识别服务将执行文本转语音,并将文本和音频发送到前端。
通过这种简单的方法,我们很快意识到向最终用户显示文本存在延迟,因为代理正在等待响应文本转换为音频。因此,我们改用让对话管理服务异步调用语音服务,告诉它开始计算响应的音频,并为要播放的每个音频段返回确定生成的 URL。UI 使用这些 URL 从语音服务获取要播放的音频。在音频准备就绪之前,UI 可能需要稍等片刻,但至少最终用户会看到一些结果,而不必等待音频段准备就绪。
此优化还有助于减少语音服务的负载,因为对语音服务的请求要短得多,因为它们不需要在向对话管理层发出请求的整个持续时间内持续。
您可能已经注意到,输出是分段播放的。我们仍在尝试不同的方法将文本拆分为多个段,以最大程度地减少段之间的延迟。我们可能会决定按句子拆分,并且可能会在它们自己的段中放置前几个单词,以便我们可以尽快开始播放音频,而不是等待生成第一个完整的句子。
深入探讨:如何使用 SignalR?我们为每个用户的消息使用一个连接对于具有使用 SignalR 或 WebSockets 经验的开发人员来说,这可能会让他们感到奇怪。对于游戏,应保持 WebSocket 连接处于打开状态,因为您希望最大程度地减少用户输入的延迟。然而,在我们的例子中,用户发送新消息可能需要几秒钟或几分钟,如果他们这样做的话。因此,保持连接打开是不值得的。无论如何,该模型都需要一段时间才能完全生成响应,这使得重用同一连接所节省的费用微不足道。
除了这个考虑之外,还有其他原因使这个决定适合我们。客户端更容易管理,因为它们不需要保留对连接的引用,也不需要在发送新消息之前检查其状态以查看它是否已在处理连接。对聊天中的每条消息使用单独的连接,可以在测试时更轻松地调试我们的代码,因为您可以在 DevTools 中打开浏览器的“网络”选项卡,并在其自己的行
微软计划使用SignalR和其他开源工具构建AI驱动的Microsoft Copilot相关教程
-
 微软更新服务条款:提醒用户谨慎使用AI工具,保护个人隐私与数据安全
微软更新服务条款:提醒用户谨慎使用AI工具,保护个人隐私与数据安全2024-08-19
-
 微软的估值和人工智能的潜力:探索微软的市值和AI技术的前景
微软的估值和人工智能的潜力:探索微软的市值和AI技术的前景2023-12-10
-
 微软Copilot:生成式AI工具或将于2024迎来爆发,成为最大赢家
微软Copilot:生成式AI工具或将于2024迎来爆发,成为最大赢家2023-12-26
-
 AMD预计2025年将开始使用openSIL,取代AGESA,引入Zen 6架构芯片支持
AMD预计2025年将开始使用openSIL,取代AGESA,引入Zen 6架构芯片支持2024-09-06
- 微软发布新壁纸庆祝 Windows Insider 计划启动十周年,限时下载!
- 微软比尔·盖茨预测AI将使每周工作三天成为可能
- “唯一给予微软卖出评级的机构投降!探索AI货币化前景,华尔街青睐微软”
- 微软将在五月公布新的 Windows 和云 AI 功能,助力用户体验升级
- 马斯克诉讼引发AI领域关注,扎克伯格亚洲之行、OpenAI扩张、微软AI工具也备受瞩目
- 微软传联合OpenAI斥7800亿建数据中心,开发AI超级电脑
- 每小时用8度电,NVIDIA Blackwell B200又一参数细节曝光!- 最新消息
- 2024年手机CPU性能排名:骁龙8至尊版称霸,A18Pro仅列第三
- 消息称FTC准备对微软云计算业务展开反竞争行为调查,微软云计算业务或将面临反竞争调查
- 英特尔至强6性能核处理器:重返数据中心CPU王座!
- 微软总裁史密斯:中国在技术发展领域正赶超西方,技术实力逐渐崛起
- 手机处理器分段?网友:从低到高,CPU段位大揭秘!手机处理器排名一览
系统资讯推荐
- 1 每小时用8度电,NVIDIA Blackwell B200又一参数细节曝光!- 最新消息
- 2 消息称FTC准备对微软云计算业务展开反竞争行为调查,微软云计算业务或将面临反竞争调查
- 3 NVIDIA App整合GeForce Experience和控制面板,Beta测试结束
- 4 详细步骤教你如何安装Win10系统,轻松搞定安装Win10系统的方法
- 5 详细步骤教你如何安全更换电脑CPU,实用指南
- 6 如何有效升级显卡以提升游戏性能和视觉体验,游戏显卡升级攻略
- 7 详细步骤教你如何安装Windows系统并解决常见问题,轻松搞定电脑重装
- 8 英特尔Battlemage GPU消息汇总 能打AMD英伟达吗?细节曝光
- 9 英伟达超越苹果,成为市值3.6万亿美元的首家上市公司历史性时刻
- 10 现役旗舰顶级CPU风冷!吊不吊,你说了算!最全面评测
win10系统推荐
系统教程推荐
- 1 edifier蓝牙耳机怎么调音量 漫步者蓝牙耳机音量调节技巧
- 2 电脑怎么往苹果手机里传视频 电脑视频传到苹果手机步骤
- 3 adobe acrobat怎么设置中文 Adobe Acrobat DC怎么切换语言为中文
- 4 c盘里用户可以删除吗 Win10电脑C盘用户文件夹删除文件的方法
- 5 win10怎么取消文件共享 Win10如何关闭文件夹共享功能
- 6 win11usb经常无法识别 Win11系统安装U盘无法识别解决方法
- 7 电脑蓝屏0x0000008e怎么修复 电脑蓝屏0x0000008e修复步骤
- 8 台式电脑支持5gwifi吗 win10如何查看电脑是否支持5G WiFi无线网
- 9 蓝牙耳机电流声大什么原因 蓝牙耳机电流声噪音消除技巧
- 10 怎么改wifi设置密码 wifi密码修改步骤